如何优化渲染引擎的性能:从全量重绘到分块缓存 #
当一个画布开始支持平移、缩放、海量图元、临时预览、局部编辑时,渲染性能问题几乎一定会出现。
最开始,大家通常都会写出一个“能跑”的版本:每次都把全部元素重新画一遍。这个版本简单、直接、容易验证正确性,但很快就会遇到瓶颈。接下来,系统通常会经历一系列演化:从全量重绘,到 retained scene tree,到命令缓存,再到 tile 分块缓存和增量更新。
这篇文章想回答三个问题:
- 画布渲染到底在做什么
- 为什么全量重绘会变慢
- 一个绘制引擎通常是如何一步步进化出缓存、裁剪和分块机制的
文中默认的场景是:
- 有一个可以平移、缩放的画布
- 画布中有大量几何元素,例如线段、矩形
- 需要支持临时预览绘制(preview)
- 目标是让 viewport 高频变化时仍然保持流畅
1. 画布绘制的本质 #
先说一个很重要的结论:
大多数绘制系统在每一帧最终都需要得到“当前帧的完整画面”,但这不等于每一帧都要“全量重建所有绘制数据”。
这两件事要分开理解:
- 重新得到当前帧画面
- 重新生成所有对象的绘制命令
这里先解释一下“绘制命令”这个词。
可以把它理解成一组非常具体的画图步骤,比如:
- 在
(10, 10)到(100, 10)之间画一条线 - 在
(40, 50)处画一个宽80、高60的矩形 - 使用蓝色描边,线宽为
2
这些“画什么、画到哪里、怎么画”的具体指令,加在一起,就是绘制命令。
所以渲染系统真正做的事情,通常不是直接操作“业务对象”,而是把业务对象转换成可执行的绘制命令,再交给底层绘制引擎。
一个高性能渲染系统的关键,不是避免“当前帧出图”,而是尽量避免“重复构建稳定内容”。
可以把绘制过程抽象成三层:
- 场景数据层
- 绘制命令层
- 画面合成层

所以,性能优化真正优化的不是“当前帧是否要显示出来”,而是:
- 尽量缓存稳定的 draw commands
- 只更新变化的数据
- 最终按当前 viewport 重新组合画面
如果换一种更工程化的说法,就是:
- 让稳定内容 stay retained
- 让变化内容 local update
- 让最终输出 cheap compose
2. 最原始的方案:每次都全量重绘 #
最直观的实现是:
- 维护一个
elements[] - 每次 render:
- 清空画布
- 遍历全部元素
- 把每个元素画出来
伪代码:
function render(canvas, elements, viewport) {
clear(canvas);
applyViewport(canvas, viewport);
for (const element of elements) {
drawElement(canvas, element);
}
}
这种方案的优点是:
- 简单
- 直接
- 调试容易
但缺点也很明显:
- viewport 平移一次,仍然要遍历全部元素
- 缩放一次,仍然要重画全部元素
- 元素越多,性能越差
如果元素数量是 N,那么每次 render 的成本接近:
- 时间复杂度:
O(N)
对于 CAD、地图、流程图、白板这类大画布应用,这是第一阶段几乎必然会撞到的瓶颈。
你会发现一个典型现象:
- 元素本身没变
- 只是 viewport 平移了一下
- 但系统还是老老实实把所有元素又画了一遍
从“正确性”角度它没有问题,但从“效率”角度,这显然是在重复做稳定工作。
3. 组件式 retained 渲染:把对象留在场景树里 #
第二阶段通常会转向 retained mode。
思路是:
- 每个 element 不再在每次 render 时手动绘制
- 而是变成 retained scene tree 里的一个节点
- viewport 变化时,通过一个上层
Group transform统一变换
例如:
<Canvas>
<Group transform={viewportTransform}>
{elements.map((element) => renderNode(element))}
</Group>
</Canvas>
这个阶段的优势在于,系统开始把“场景结构”和“当前帧出图”分离:
- 场景结构 retained
- viewport 变化不需要重新写整套 JS 绘制逻辑
- 对中小规模场景非常有效
但它并不意味着“内部完全冻结”。
更准确地说:
- 不重建对象结构
- 但最终当前帧仍然要根据新 transform 重新生成显示结果
这点和 Three.js、原生 UI scene tree 很像:
- 结构 retained
- 变换传播
- 最终按当前帧重新 draw / compose
retained 方案的问题 #
当 element 数量很多时,问题会变成:
- 场景树节点太多
- viewport 高频变化时,仍然要处理大量子节点
这里的“处理子节点”并不是说每次都把子节点从头创建一遍,而是指这些子节点通常仍然要参与当前帧的渲染流程,例如:
- 遍历节点
- 传播父级 transform
- 参与当前帧的绘制或合成
也就是说,retained 方案解决的是:
- 不反复重建场景结构
但它还没有完全解决:
- viewport 变化时,如何减少对子节点的逐个处理
这就是为什么第三步之后,通常还需要第四步:
- 第三步缓存了“对象结构”
- 但第四步要开始缓存“一组对象的整体绘制结果”
也就是:不只是把对象留在场景树里,而是把一部分稳定内容提前录好,后面直接复用。
这里要特别强调一个容易混淆的点:
第四步不是“给每个 child 都单独缓存一个 picture”,而是“把一组稳定的 child 合并成一个更粗粒度的 picture”。
如果只是每个 child 各自缓存 picture,但每一帧仍然要:
- 遍历全部 children
- 传播 transform
- 逐个
drawPicture(child.picture)
那么第三步里最主要的处理成本其实并没有真正减少。
所以第三步和第四步的真正区别是:
- 第三步:处理单位还是 child
- 第四步:处理单位提升成 group / layer / document picture
4. 命令式缓存:把一组稳定内容冻结成一个 picture #
比 retained 更进一步的优化,是把一组稳定内容的绘制结果描述提前录下来,并在后续帧中直接复用。
以 Skia 为例,可以把一组绘制命令录制成 SkPicture。
你可以把 SkPicture 理解成:
- 一段已经录好的绘制指令
- 后续可以重复拿来画
于是渲染逻辑会变成:
- 稳定内容先录成 picture
- render 时直接画 picture
const picture = recordScene(elements);
function render(canvas, viewport) {
clear(canvas);
applyViewport(canvas, viewport);
canvas.drawPicture(picture);
}
这已经非常接近“冻结绘制内容”的思路了:
- 内容稳定时,不再重建这组内容的绘制命令
- viewport 变化时,只改变外部 transform
换句话说,第四步相当于把第三步里“很多子节点”进一步合并成“一个更粗粒度的可复用单元”。
如果说第三步更像:
- 很多 retained 子节点组成一个场景树
那么第四步更像:
- 先把这批稳定子节点录成一张 picture
- 后面优先复用这张 picture
因此,第四步相比第三步真正减少的工作是:
- 不再逐个 child 参与当前帧的绘制提交
- 不再逐个 child 作为渲染处理单位
- viewport 变化时,更多是“整组 picture 的 transform 与绘制”
这就是第四步的真正优化点。
它解决了什么 #
- 元素不变时,不需要重录绘制命令
- viewport 变化时,可以只改 transform
它的问题 #
如果整个文档都录成一张大 picture:
- 文档任何一个局部变化,都可能导致整张 picture 重录
- 画面越大,局部修改成本越高
也就是说,第四步解决了“不要每次都逐个处理子节点”的问题,但还没解决另一个问题:
- 缓存粒度太粗
一旦只改了文档里很小的一块区域,却要重录整张大 picture,就会产生新的浪费。
所以如果场景继续变大,就必须继续问一个更细的问题:
缓存应该缓存到什么粒度?
整张文档一张 picture,通常仍然太粗。
5. 真正适合大画布的方案:Tile 分块缓存 #
这是很多中大型 2D 编辑器、地图类应用、大画布系统里最实用的一步。
核心思路:
- 不把整个 document 录成一张 picture
- 而是把世界坐标空间切成 tile
- 每个 tile 缓存一张 picture
- render 时只画可见 tile
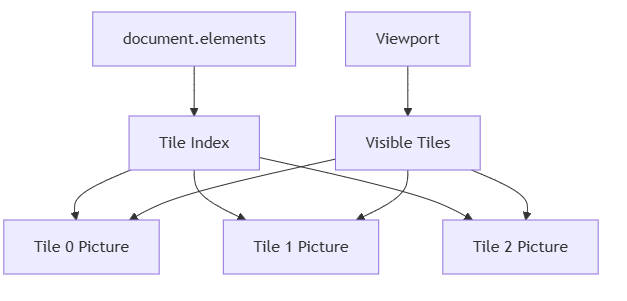
最终 render 的形态:
<Canvas>
<Picture picture={gridPicture} />
<Group transform={viewportTransform}>
{visibleTiles.map((tile) => (
<Picture key={tile.id} picture={tile.picture} />
))}
</Group>
<Picture picture={toolPicture} />
</Canvas>
这套方案的关键收益不在于“从此完全不重绘”,而在于把问题从:
- 每次面对全部 element,或者面对一整张巨大的 document picture
变成:
- 每次只面对当前可见 tile
于是最终开销会集中在“局部缓存命中”和“局部重建”上。
这一步是在第四步基础上的继续优化:
- 第四步已经把一组对象冻结成 picture
- 第五步继续把“大 picture”拆成“很多小 picture”
于是它补足了第四步的两个短板:
- 只改一小块内容时,不必重录整张大 picture
- viewport 变化时,不必处理不可见区域的 picture
这套方案的关键收益:
- viewport 变化时:
- 不再关心全部 elements
- 只关心可见 tile
- 文档局部变化时:
- 只让受影响 tile 变脏
- 只重建局部 tile picture
复杂度变化 #
原始方案:
- 每次 render:
O(N)
Tile 方案:
- render 时主要变成:
O(V) V是可见 tile 数量,而不是元素总数
只要 tile 粒度设计合理,V 通常会远小于 N。
所以第五步其实是在第四步的基础上继续细化:
- 第四步:把稳定内容冻结成 picture
- 第五步:不要只冻结成一整张大 picture,而是冻结成很多小块 picture
这样带来的改进是:
- viewport 变化时,只画当前屏幕能看到的那些小块
- 局部修改时,也只重建受影响的小块
你可以把这两步的关系理解成:
- 第四步解决“要不要缓存”
- 第五步解决“缓存到多细才合理”
6. Tile 方案里的两个关键问题 #
6.1 如何确定元素属于哪些 tile #
对每个 element,先计算 world-space bounds:
- 线段:取端点最小/最大值
- 矩形:取规范化后的 bounding box
再根据 tileSize 计算它覆盖哪些 tile。
例如:
minCol = floor(minX / tileSize);
maxCol = floor(maxX / tileSize);
minRow = floor(minY / tileSize);
maxRow = floor(maxY / tileSize);
然后把这个 element 分配到所有覆盖的 tile。
6.2 跨 tile 元素会不会重复绘制 #
会,如果处理不当。
例如一条长线跨过两个 tile:
- Tile A 录图时画一次
- Tile B 录图时又画一次
如果不做处理,重叠区域会重复上色。
正确做法是:
- 元素可以分配到多个 tile
- 但 tile 在录图时必须先 clip 到自己的 bounds
也就是:
canvas.clipRect(tileBounds);
drawElementsInsideTile();
这样每个 tile 只画自己区域内的内容。
这里有一个非常重要的工程判断:
- 元素可以跨 tile
- 但同一个屏幕区域不能被重复上色
所以“多 tile 分配 + tile clip”必须成对出现。
7. 从“全量同步”到“增量更新” #
很多 tile 架构一开始会犯的错误是:
- render 时全量
sync(document.elements) - sync 内部重新遍历所有元素、重新算 bounds、重新映射 tile
这会导致:
- render 热路径很重
- 状态系统(如 MobX)会收集大量不必要依赖
- viewport 更新时又回到了“接近全量扫描”的问题
更好的做法 #
不要在 render 里做全量同步,而要改成:
- 文档变化时,走增量 API 更新 tile store
- render 时只读取稳定的 visible tile pictures
伪代码:
tileStore.addElement(element);
tileStore.addElements(elements);
tileStore.removeElement(id);
tileStore.updateElementGeometry(element);
tileStore.clear();
这样 render 就只做:
- 计算 visible tile
- 画 tile pictures
而不再负责:
- 全量元素扫描
- bounds 重算
- tile 重新分配
这一步对性能提升非常关键,因为它把系统真正分成了两条路径:
- 写路径:增量更新索引与缓存
- 读路径:快速读取可见 tile pictures
一旦这两条路径分开,viewport 变化就不再天然等于“全量同步”。
8. 一种典型的工程化拆分方式 #
一个干净的 tile 渲染系统,通常会拆成这些对象:
DocumentTileStore #
职责:
- 管理 element -> tile 的映射
- 管理 tile cache
- 输出 visible tile pictures
TilePictureCache #
职责:
- 表示单个 tile 的缓存实体
- 持有 tile bounds、elementIds、picture、dirty 状态
TileRenderer #
职责:
- 录制单个 tile 的 picture
- 内部执行 clip + 元素绘制
VisibleTileResolver #
职责:
- 根据 viewport + 屏幕大小
- 计算当前可见 tile IDs
DocumentTileBridge #
职责:
- 作为 document 写入与 tile store 增量同步的桥接层
- 避免在
Scene.render()中做全量同步
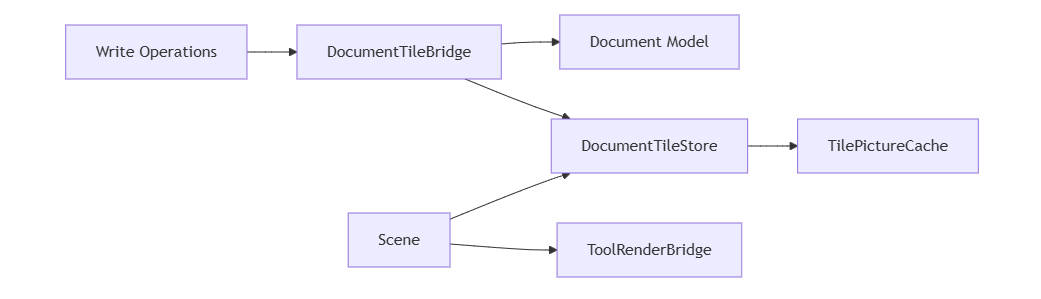
这个拆分的价值在于:
- model 层不直接承担渲染缓存职责
- render 层不负责全量同步 document
- tile store 成为“文档空间缓存”的专职对象
9. 与成熟引擎的类比 #
9.1 HTML5 Canvas 2D #
最基础的 Canvas 2D 常见做法是:
- 每帧清空
- 每帧重画全部内容
如果项目复杂了,业务层通常会自己引入:
- 离屏 canvas
- 分层 canvas
- tile cache
- dirty rect
也就是说,Canvas 2D 本身不会自动帮你做高层缓存,优化要自己设计。
9.2 React Native Skia #
Skia 既支持 retained mode,也支持 immediate mode。
- retained mode:适合结构稳定的场景树
- immediate mode:适合动态绘制命令
而 SkPicture 则提供了一种非常适合做缓存的中间形态:
- 录一次
- 多次复用
tile picture cache 就是在应用层利用这点做出来的。
9.3 Three.js #
Three.js 的 scene graph 是 retained 的:
- 不会每帧重建对象
- 会复用 geometry / material / texture
- root transform 变化时,更多是矩阵传播与重新 draw
但 Three.js 也不是天然“把整棵子树冻结成一张位图后只平移”。
如果要真正达到类似“freeze drawing”的效果,通常也要借助:
- render-to-texture
- tile cache
- batching
- 分层合成
所以从思想上说,tile cache 更接近:
- 把 document 切成高层场景单元
- 每个单元缓存 draw commands
- viewport 变化时重新组合这些单元
9.4 原生 UI / 浏览器渲染引擎 #
浏览器、iOS Core Animation、Android RenderThread 等成熟引擎,通常都在做类似的事:
- 稳定内容 retained
- 变化内容局部更新
- 最终通过 compositor 组合当前帧
不同之处只在于:
- 缓存的粒度
- 缓存存放的位置(CPU / GPU / layer)
- 最终组合是在应用层还是引擎层完成
10. 画布性能优化的通用路径 #
把整个过程抽象出来,渲染系统通常会沿着下面这条路线演化:
阶段 1:全量重绘 #
- 最简单
- 最容易写
- 最先遇到性能瓶颈
阶段 2:retained 场景树 #
- 对象结构常驻
- 适合中小规模场景
- viewport 高频变化时比全量 immediate 更好
阶段 3:命令缓存 / picture 缓存 #
- 避免每帧重建稳定 draw commands
- 适合局部稳定的场景
阶段 4:tile 分块缓存 #
- 把缓存粒度从“整文档”缩小到“子区域”
- 适合大画布、地图、CAD
阶段 5:增量更新 + 可见性裁剪 #
- 不在 render 做全量同步
- 只处理可见区域
- 只重建脏 tile
阶段 6:更高级优化 #
- 大对象分流
- tile LRU
- batching
- GPU/compositor 级缓存
11. 一张总结图 #
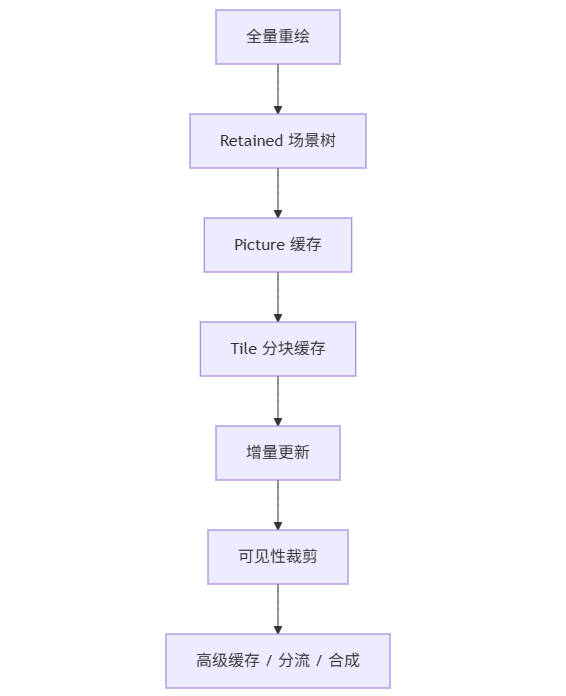
可以看到,优化不是一次性的“开个开关”,而是逐层降低“每帧必须重新做的事情”。
真正高性能的核心问题始终是:
哪些内容是稳定的? 哪些内容是变化的? 如何只更新变化的部分?
12. 实践建议 #
如果你正在实现一个类似 CAD、白板、流程图、地图的系统,可以按这个顺序思考:
- 先做出正确的全量重绘版本
- 再识别 viewport 变化是不是主要瓶颈
- 如果是,先考虑 retained tree
- 如果 retained tree 仍然不够,再上 picture cache
- 如果文档更大,再做 tile cache
- 当 tile 也吃紧时,再做大对象分流和更细的生命周期管理
不要一开始就上最复杂方案,但也不要把所有性能问题都寄希望于一个框架的“自动优化”。
真正决定性能上限的,往往是你如何组织:
- 数据结构
- 缓存粒度
- 更新路径
- 合成路径
13. 结语 #
渲染优化的本质,并不是“让画面不再重绘”,而是:
- 让稳定内容尽量不重建
- 让变化内容局部更新
- 让最终画面组合尽量轻量
从全量重绘,到 retained scene graph,再到 tile picture cache,本质都是在回答同一个问题:
如何把一帧里真正需要做的工作,压缩到最少。
如果站在这个角度去看,不同绘制引擎之间的差别,更多只是:
- 缓存做在哪一层
- 组合做在哪一层
- 哪些能力由引擎提供,哪些需要业务自己设计
而优化思路本身,是共通的。
如果把全文压缩成一句话,那就是:
渲染引擎的优化,不是逃避当前帧,而是尽量少做当前帧里本不该重复做的工作。
这也是从全量重绘,走向 retained tree、picture cache、tile cache、增量更新的真正内核。
(完)